前言
Python3爬虫可以模拟浏览器的行为,访问网页并从中提取数据。主要应用在数据采集、搜索引擎优化、价格比较、舆情分析等领域。工作流程:
1.首先发送HTTP请求到目标网站,可以通过Python的requests库实现。
2.解析HTML内容,从中提取有用的信息。常用解析库:BeautifulSoup和lxml
3.选择合适的爬虫框架来简化任务。推荐流行框架:Scrapy
4.使用爬虫框架,定义爬取规则和提取数据的方式。
5.存储和处理数据
安装Python和pip
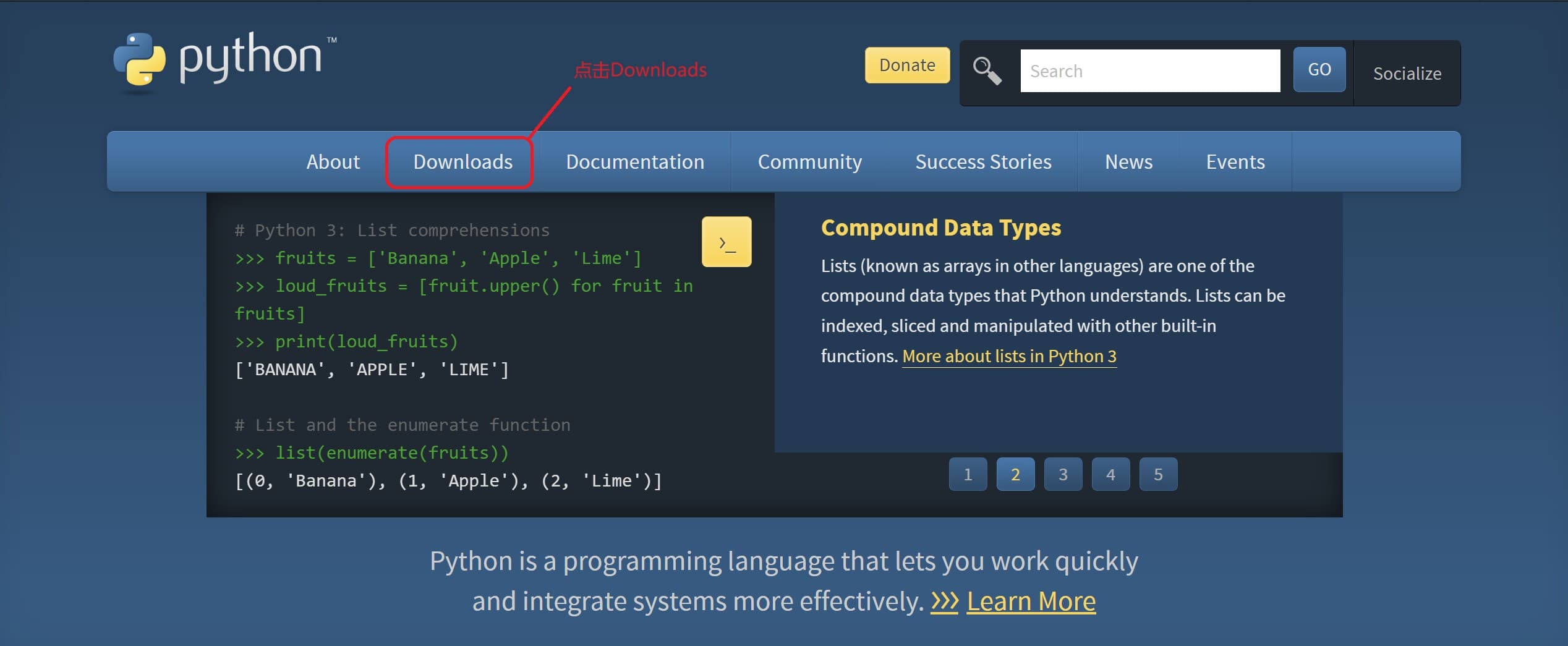
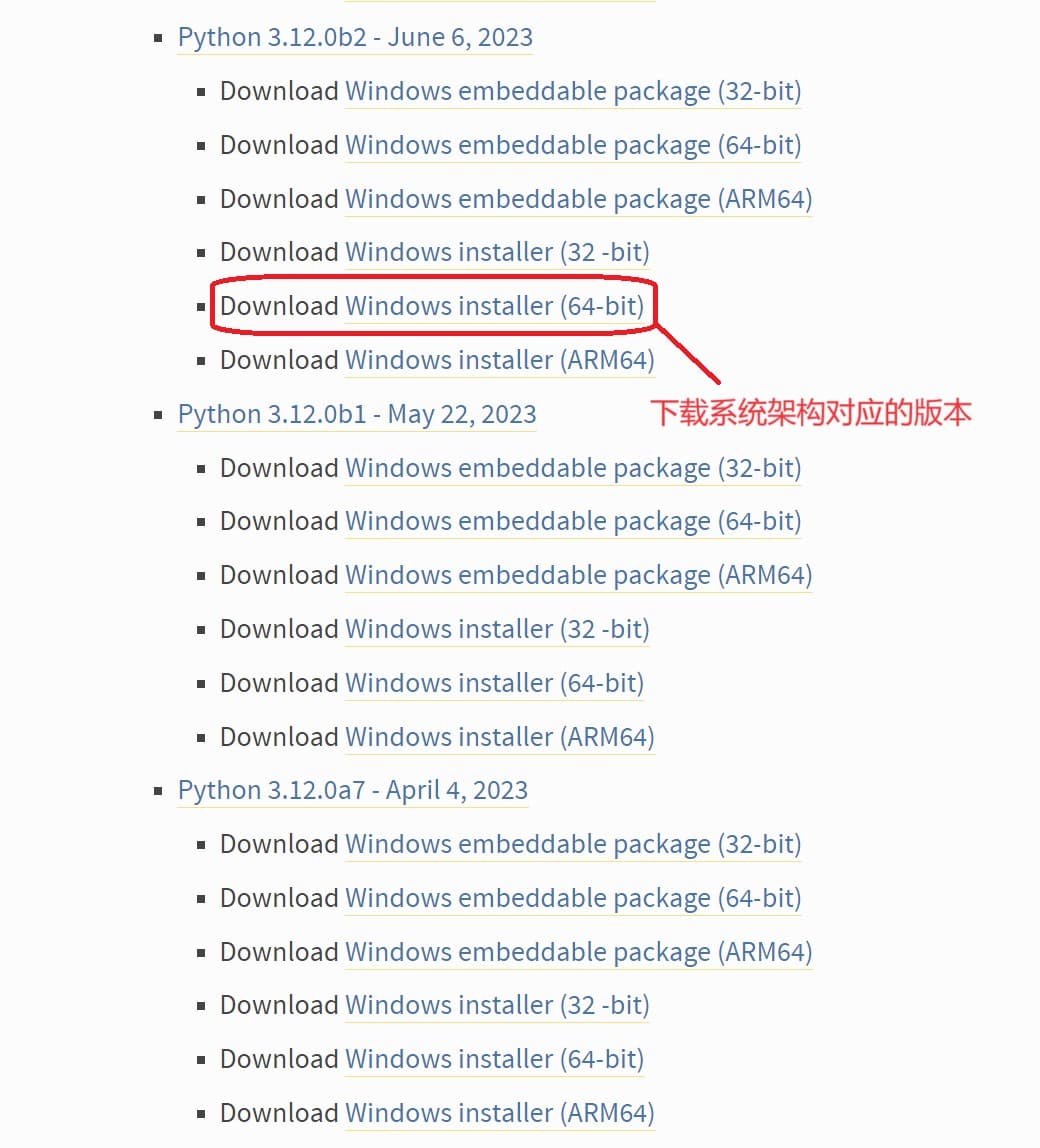
1.打开Python官网,点击 “Downloads”,选择操作系统,下载最新的Python3版本即可
注:下载后运行可执行文件安装Python,一路默认。唯一要确保勾选”Add Python 3.x to PATH”选项,添加环境变量。
2.Win+R 打开命令提示符(CMD),输入以下命令安装pip
1
2
3
4
5
|
python -m ensurepip --default-pip
pip --version
|
3.补充:Linux系统安装,以Ubuntu举例
1
2
3
4
5
6
7
8
9
10
11
12
|
sudo apt update
sudo apt install python3
python3 --version
sudo apt install python3-pip
pip3 --version
|
Scrapy安装和初始化
1.Win+R 打开命令提示符(CMD),复制粘贴以下命令
2.在终端中,创建新的目录存放爬虫项目
1
2
3
4
5
|
scrapy startproject my_scrapy_project
cd my_scrapy_project
|
补充:使用虚拟环境安装(推荐)
相比常规安装,使用虚拟环境安装有如下几个优点:
- 隔离依赖:通过创建虚拟环境,可以在项目级别管理和安装依赖,而不会影响到系统级别的Python环境。
- 版本一致性:虚拟环境可以确保项目使用的是指定版本的Python解释器和第三方库,避免在不同环境中出现版本不一致的问题。
- 轻松迁移:使用虚拟环境便于将项目迁移到其它主机,无需担心依赖关系。
- 方便清理:不需要项目时,可以简单粗暴地删除虚拟环境文件夹,而无需担心对系统环境的影响。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
python -m venv venv
venv\Scripts\activate
pip install scrapy
scrapy startproject my_spider_project
cd my_scrapy_project
|
3.在项目目录下,创建爬虫
1
2
|
scrapy genspider example_spider example.com
|
4.编辑爬虫规则:my_scrapy_project/spiders/example_spider.py
1
2
|
code my_scrapy_project/spiders/example_spider.py
|
5.运行爬虫
1
2
|
scrapy crawl example_spider
|
以豆瓣图书为例,一个完整的Scrapy项目
一、项目结构
1
2
3
4
5
6
7
8
9
10
11
12
13
| my_douban_books_project/
│
├── my_douban_books_spider/
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
│ ├── __init__.py
│ └── douban_books_spider.py
│
└── scrapy.cfg
|
二、文件说明
1.定义爬虫需要提取的数据结构:my_douban_books_spider/items.py
1
2
3
4
5
| import scrapy
class MyDoubanBooksProjectItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
|
2.编辑爬虫文件:my_douban_books_spider/spiders/douban_books_spider.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import scrapy
from my_douban_books_spider.items import MyDoubanBooksProjectItem
class DoubanBooksSpider(scrapy.Spider):
name = 'douban_books'
start_urls = ['https://book.douban.com/']
def parse(self, response):
for book in response.css('li.subject-item'):
item = MyDoubanBooksProjectItem()
item['title'] = book.css('h2 span::text').get()
item['author'] = book.css('.pub::text').get()
yield item
next_page = response.css('span.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
|
3.配置可选项
1
2
3
4
5
6
7
8
9
10
11
|
my_douban_books_spider/middlewares.py
my_douban_books_spider/pipelines.py
my_douban_books_spider/settings.py
scrapy.cfg
|
4.打开命令行窗口,运行已配置好的爬虫
1
2
3
4
5
|
cd path\to\my_douban_books_project
scrapy crawl douban_books
|
注:请以学习目的为主,确保爬虫行为符合豆瓣的使用政策,遵循相关规定,并设置适当的爬取速率以避免对服务器造成不良影响。